Monitoring software quality metrics is essential for building reliable and high-performing applications. By tracking the right software metrics, teams can identify issues early, streamline development, and ensure software meets user expectations.
In 2020, U.S. companies lost $2.08 trillion due to software failures, bugs, and poor development practices (CISQ Report). Yet, many software teams (and a lot of enterprises) still struggle to track the right software quality metrics leading to numerous challenges like missed deadlines, rising costs, and frustrated users.
This article will give you clear, actionable answers to every possible question you have regarding software quality metrics. You’ll get acquainted with:
✅ The 10 key software quality metrics that top-performing teams use.
✅ How to track, measure, and improve them.
✅ Why these metrics directly impact reliability, security, and user experience.
Key insights
- Tracking software quality metrics ensures better performance, security, and user experience.
- Choosing the right metrics prevents unnecessary overhead and improves decision-making.
- Defect density, test coverage, and MTTR are crucial for stability and reliability.
- A data-driven approach helps prevent post-release failures and enhances software maintainability.
- Companies that prioritize code quality and user satisfaction deliver better products with fewer long-term costs.
- High-performing teams use software metrics to enhance security, minimize downtime, and accelerate development cycles.
By the end, you’ll have a data-backed strategy to make smarter decisions, build better software, and reduce costly issues before they reach your users. Before we get into the details, it’s crucial to first understand what software quality metrics are and why they are important.
What are Software Quality Metrics?
Software metrics are measurable indicators that assess the effectiveness, reliability, and performance of a software product.
They provide objective data on critical aspects such as code quality, maintainability, security, and user satisfaction. Software quality metrics provide quantifiable data to help teams make informed decisions, track progress, and optimize their workflows.
But not all software metrics are equally useful. Some provide clear, actionable insights that help teams improve performance, security, and user experience, while others create unnecessary noise.
Types of Software Quality Metrics
To effectively monitor software quality, software quality metrics are classified into three main categories:

Product Metrics
Product metrics evaluate the inherent quality of the software, focusing on aspects like code structure, defect occurrence, performance, and security vulnerabilities. They help assess how well the software functions and its overall robustness.
Process Metrics
Process metrics focus on the effectiveness of development and testing workflows, measuring how efficiently software is developed, tested, and maintained. They highlight how well issues are identified, addressed, and resolved.
Project Metrics
Project metrics assess the overall project health, including software deployment frequency, user satisfaction, and resource management. They help evaluate the efficiency of project execution and its impact on end-users.
10 Software Development Quality Metrics That Matter
There are countless ways to measure software quality, but tracking everything doesn’t mean building better software. The key is focusing on metrics that provide real insight into software stability, performance, and maintainability. That’s why we have broken down the 10 most critical metrics one by one.
Below are 10 essential software quality metrics help software professionals evaluate software quality, performance, and maintainability, allowing them to prevent failures, streamline development, and ensure long-term software success
Code Quality and Maintainability (Eliminate Technical Debt Before It Slows You Down)
Every software application, whether a modern cloud-based system or a legacy IBM i platform, relies on well-structured and efficient code. Poorly written code leads to frequent defects, increased debugging time, and higher long-term maintenance costs. On the other hand, high-quality code ensures faster development cycles, easier scalability, and long-term software reliability.
What is Code Quality?
Code quality refers to how well-written, maintainable, and error-free a codebase is.
High-quality code is:
- Readable – Easy to understand for both current and future developers.
- Maintainable – Can be updated and modified without introducing unexpected issues.
- Efficient – Optimized for performance and avoids unnecessary complexity.
- Secure – Protects against vulnerabilities and follows security best practices.
Without a structured approach to maintaining code quality, enterprise applications, including IBM i systems, can become difficult to modernize and scale, leading to significant business risks.
How to Measure Code Quality
Code quality is assessed using static code analysis tools that scan source code for complexity, maintainability, duplication, and security vulnerabilities.
Improving code quality requires consistent processes, automated tools, and strong development standards. Some key strategies include:
- Implement automated code reviews in CI/CD pipelines to catch issues before deployment.
- Follow a modular architecture to reduce dependencies and simplify code updates.
- Refactor legacy code incrementally instead of attempting full rewrites, which are costly and risky.
- Adopt secure coding guidelines to prevent vulnerabilities from entering production.
When the code is structured properly, debugging, testing, and scaling become simpler. Developers spend less time firefighting and more time delivering value.
Test Coverage and Defect Detection – Catch Issues Early, Reduce Failures Later
Even the most well-structured software contains defects.
Test coverage is one of the most reliable ways to measure how well a software system is validated before deployment. For IBM i applications, test coverage is particularly important because many legacy systems were built with minimal automated testing frameworks. Without proper validation, these applications risk unexpected failures and costly downtime.
What is Test Coverage?
Test coverage measures the percentage of an application’s code that is executed during automated tests. It helps teams determine whether critical functions have been tested and validated before release.
A high test coverage percentage suggests that most of the application is validated, while a low percentage means significant portions of the software remain untested.
How to Measure Test Coverage (With Formulas)
Several types of test coverage provide different insights into the thoroughness of software validation.
A well-tested system requires more than just high coverage percentages. It requires meaningful, well-designed tests that accurately reflect how the software is used in real-world conditions.
Defect Density and Production Stability – Fix the Most Costly Bugs First
Software defects are inevitable, but the way teams detect, track, and resolve them determines whether an application remains stable or becomes a long-term liability. Defect density is one of the most effective ways to measure software quality before deployment. It provides insight into how frequently defects occur relative to the size of the codebase, allowing teams to make informed decisions about release readiness.
Many enterprises struggle with legacy codebases where technical debt impacts software quality, making updates more difficult and risky.
A well-maintained system does not just have fewer defects; it has a controlled defect rate, where issues are caught early, resolved quickly, and prevented from recurring.
How Defect Density is Measured
Defect density is calculated using the formula:

A lower defect density suggests better software reliability, while a higher value indicates potential stability risks. However, defect density should always be analyzed in the context of some applications, like enterprise financial software, which requires near-zero defects, whereas experimental software might tolerate higher defect rates.
Mean Time to Recovery (MTTR) – Minimize Downtime, Restore Service Faster
Even with rigorous testing, software failures are inevitable.
The true measure of system reliability is not just how often failures occur but how quickly they are resolved. Mean Time to Recovery (MTTR) tracks the average time it takes to detect, diagnose, and fix an issue in production, ensuring minimal downtime and business disruption. For cloud services, MTTR is often under 30 minutes. For enterprise software, it can stretch to several hours. If your team’s MTTR regularly exceeds 4-6 hours, you have a bottleneck somewhere, either in detection, diagnosis, or deployment speed.
How to Measure MTTR
- Automated monitoring tools (Datadog, Splunk) detect issues before users do.
- Incident response tools (PagerDuty, OpsGenie) track resolution times.
- Incident tracking systems streamline resolution and assign responsibility.
- Post-mortem reports help refine troubleshooting strategies for future incidents.
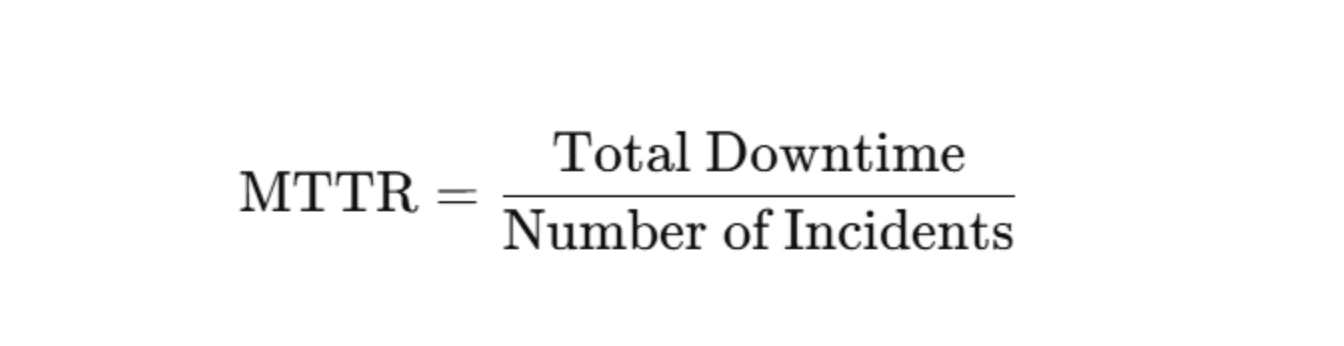
Faster recovery time reduces financial losses, improves user experience, and strengthens system resilience. Companies that integrate AI-driven alerts, predictive maintenance, and DevOps best practices consistently achieve lower MTTR, ensuring high availability and long-term software stability.
Lead Time for Changes – Deliver Features Without Delays
For high-performing software teams, speed is everything because speed and stability go hand in hand in software development.
Lead Time for Changes measures how quickly teams can take a code change from development to production, reflecting the efficiency of a team’s workflow. Long lead times often point to bottlenecks in testing, approval processes, or inefficient CI/CD pipelines. A shorter lead time allows businesses to deliver updates faster, while a longer lead time can indicate bottlenecks in testing, approvals, or deployment. Tracking lead time helps identify delays and streamline the development process.
How to Measure Lead Time for Changes
- CI/CD pipelines (Jenkins, GitHub Actions) measure commit-to-deployment time.
- Code review analytics track bottlenecks in the approval process.
- Deployment automation removes unnecessary manual steps to speed up delivery.

When lead times are optimized, teams can move features from development to production faster without compromising quality. In large-scale enterprise environments, software development estimation plays a crucial role in ensuring that development efforts align with business needs, preventing unnecessary rework and improving overall efficiency.
Customer-Reported Bugs – Prevent Users from Becoming Your Testers
When users find bugs, it’s a clear sign that your testing and monitoring processes need improvement.
High rates of customer-reported bugs suggest gaps in testing coverage or pre-release validation.Instead of waiting for users to discover problems, teams should focus on identifying and resolving issues proactively.
How to Measure Customer-Reported Bugs
- Real-time error monitoring tools (Sentry, Rollbar) catch failures before users do.
- Beta testing and staged rollouts help detect issues in controlled environments.
- Automated UI and regression tests prevent recurring defects.
How to Improve It
- Implement real-time error monitoring to catch bugs early.
- Increase beta testing and User Acceptance Testing (UAT) before major releases.
- Expand automated test coverage in high-risk areas.
By resolving issues before customers encounter them, teams can enhance user satisfaction and reduce support costs.
Release Frequency and Deployment Stability – Ship Updates with Confidence
Frequent software updates indicate an agile and efficient development process, but uncontrolled or unstable releases can introduce defects and disrupt user experience. Release Frequency measures how often teams deploy new features, fixes, or updates, providing insight into development speed, process maturity, and software stability.
How Release Frequency is Measured
Release frequency is tracked using the formula:

A higher release frequency indicates a more agile development process, while a lower frequency may suggest longer development cycles or potential deployment bottlenecks.
User Satisfaction and Software Success
No matter how technically sound software is, its success ultimately depends on user experience.
User Satisfaction measures how well your software meets customer expectations, focusing on usability, performance, and reliability. A drop in satisfaction often signals performance issues, confusing interfaces, or unresolved defects.
One of the most widely used methods to measure user satisfaction is the Net Promoter Score (NPS):

How It Works
- Promoters are users who rate your software 9 or 10 on a satisfaction scale.
- Detractors are those who rate it 6 or below.
- The NPS score is calculated by subtracting the percentage of detractors from the percentage of promoters.
A higher NPS indicates strong customer satisfaction and loyalty, while a lower NPS suggests that improvements in user experience, software stability, or feature offerings may be needed.
System Availability and Uptime Reliability
Availability is a critical software metric that directly impacts business operations and user trust.
A system with frequent outages or high downtime creates financial losses and damages credibility. System Availability measures how often a system remains operational and accessible.
It is calculated using:

A higher availability percentage (e.g., 99.99% uptime) indicates a more reliable system, while lower availability suggests frequent outages, which may affect user experience and business operations.
Security Vulnerability Metrics and Risk Management
Security is an essential aspect of software quality, especially for enterprise and IBM i environments, where sensitive data is processed. Measuring security vulnerabilities helps teams identify risks, prevent breaches, and ensure compliance with industry standards.
A key security metric is Vulnerability Density, which measures how many security flaws exist per thousand lines of code (KLOC):

How Can LANSA Help?
As software systems evolve, maintaining high code quality, system reliability, and security compliance becomes more complex.
IBM i enterprises, in particular, face challenges with legacy modernization, scalability, and integration. This is where LANSA’s solutions come in. Some of the highly used and recommended ones are Visual LANSA and aXes. These tools help you streamline development, automate workflows, and enhance software quality.
Watch our webinar and learn how to solve the biggest IBM i challenges of 2026.
Visual LANSA: Modernizing Application Development
Visual LANSA provides a low-code development platform that enables faster software delivery without compromising quality. By automating routine tasks, reducing coding effort, and integrating best-in-class testing frameworks, teams using Visual LANSA can accelerate development cycles while maintaining software integrity.
aXes: Enhancing UX Without Disrupting Legacy Systems
For organizations running legacy IBM i applications, aXes provides a seamless way to enhance UI and accessibility without requiring extensive redevelopment. Instead of costly rewrites, aXes enables browser-based modernization, improving usability and customer experience while keeping back-end systems intact.
Watch our webinar and learn how to Drive Growth and Adoption Through Green Screen Modernization.
To sum it all up…
Software Quality metrics isn’t just the name of tracking numbers. It is to build software that is reliable, efficient, and easy to maintain. Metrics help, but only when used with purpose. You can have the most detailed reports, fancy dashboards, and perfectly optimized test coverage, but if your system is slow, unreliable, or frustrating to use, none of it matters.
The real purpose of tracking these metrics is not to collect data but to make better decisions.